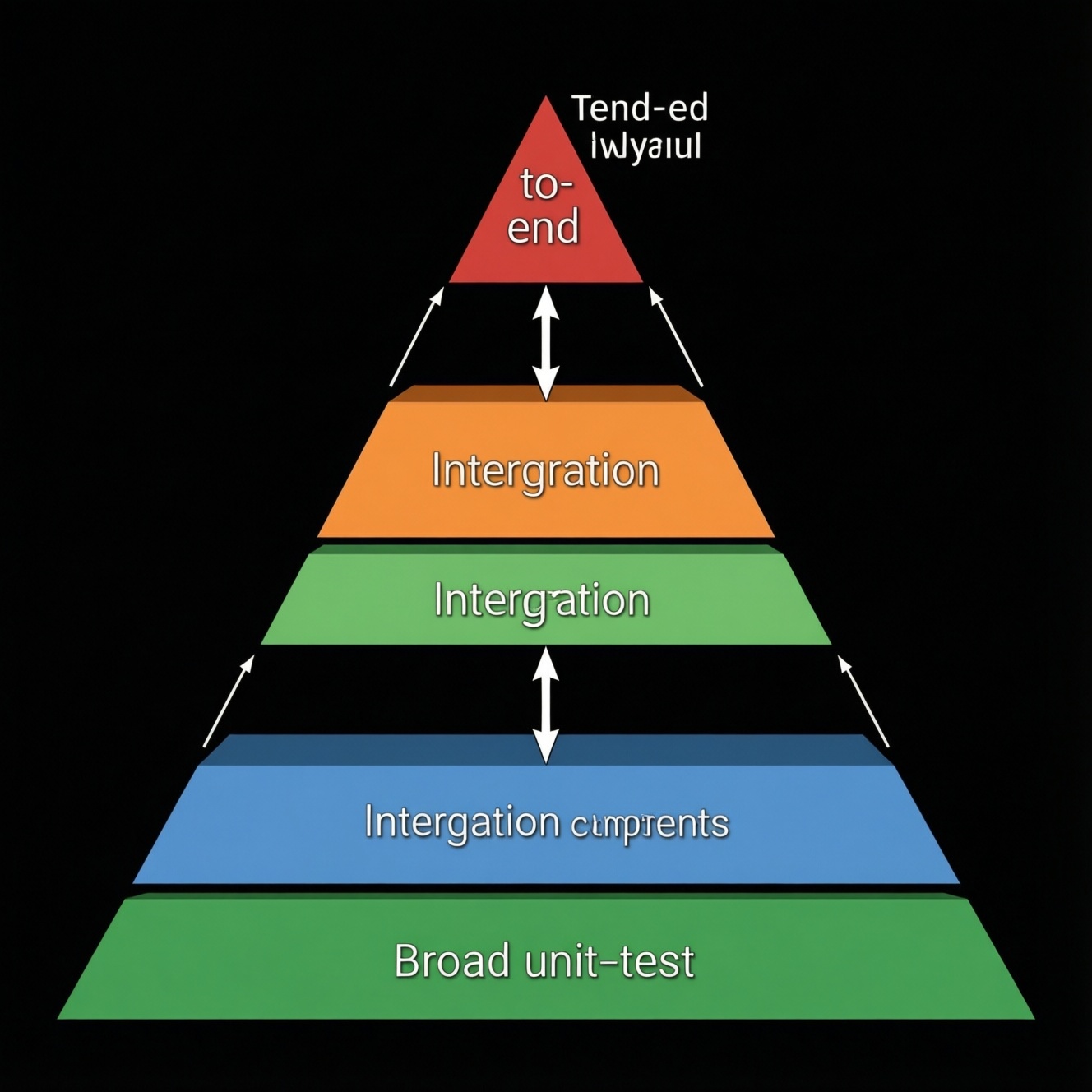
Экономное тестирование ПО строится как пирамида: максимум быстрых unit‑тестов, минимум дорогих e2e‑сценариев, а интеграционные проверки закрывают только реальные стыки. Так вы ускоряете обратную связь, снижаете хрупкость тестов и не переплачиваете временем на прогон. Ключ - явные границы, риск‑ориентированный отбор сценариев и автоматизация тестирования там, где она окупается.
Ключевые выводы по экономному тестированию
- Unit тестирование должно закрывать бизнес‑правила и ветвления, а не инфраструктуру и внешний мир.
- Интеграционное тестирование делайте по контрактам и критичным интеграциям, не превращая его в e2e "через всё".
- E2E тестирование оставляйте для нескольких пользовательских "сквозных" путей и регресса критичных денежных/правовых операций.
- Ускорение достигается приоритизацией, параллелизмом, ранней фильтрацией (линтеры/типизация) и стабильными фикстурами.
- Контрактные тесты + заглушки/фейки чаще дают лучшее соотношение время/надёжность, чем UI‑прогоны.
- Рефакторить набор тестов нужно по метрикам: время CI, флейки, цена изменения и доля "шумных" падений.
Когда достаточно unit‑тестов: критерии и ограничения
Unit‑тесты выгодны, когда проверяемая логика живёт внутри процесса и её можно изолировать от сети, БД и времени. Для intermediate‑команд это базовый слой: быстрый, предсказуемый, удобный для TDD и локального прогона.
Критерии, что unit‑тестов достаточно
- Чистая бизнес‑логика: расчёты, правила скидок/лимитов, валидации, маппинги, маршрутизация, состояния.
- Детерминизм: при одинаковых входных данных результат всегда одинаков (время/рандом/сеть инкапсулированы).
- Ясные контракты на границах: внешние зависимости скрыты за интерфейсами, их можно подменить фейками/моками.
- Цена ошибки умеренная: падение не ведёт к финансовым потерям/нарушениям SLA, либо покрыто другими слоями.
Пример из кода: что тестировать unit‑слоем
Проверяйте правила, а не транспорт. Например, функция расчёта итоговой цены должна тестироваться на наборе входов (позиции, промо, налоги), но не через HTTP‑эндпоинт и не через реальную БД. В unit тестирование выносите ветвления и исключения: отрицательное количество, истёкший промокод, лимит на корзину.
Когда unit‑тесты не спасут (и нужно подняться уровнем)
- Маппинг ORM/миграции: ошибки схемы не выявятся без реальной БД или хотя бы интеграционного слоя.
- Сериализация/совместимость API: контракты JSON/Proto и backward‑compatibility лучше ловить контрактными/интеграционными тестами.
- Конкурентность и транзакции: дедлоки, изоляция транзакций, повторные доставки сообщений - это не unit‑уровень.
- Реальные побочные эффекты: платежи, отправка писем, очереди, файловые хранилища требуют тестов на границах.
Интеграционные тесты без избыточности: как определить границы
Интеграционное тестирование экономно, если оно проверяет только "стык" и контракты между компонентами, а не весь продукт целиком. Граница - это место, где меняются протоколы, форматы данных, транзакционные гарантии или ответственность команд.
Как выбрать границы интеграционных тестов
- Выделите адаптеры и порты: всё, что ходит в БД/HTTP/очереди/кэш, оформите адаптерами и тестируйте их интеграционно.
- Определите критичные инварианты: idempotency, порядок событий, уникальность, корректность статусов, согласованность саги.
- Срежьте комбинаторику: один тест - один стык и один инвариант; остальное остаётся в unit‑уровне.
Что понадобится (доступы, инструменты, договорённости)
- Изолированное окружение: отдельные ресурсы (БД/очереди) для CI, чтобы прогоны не конфликтовали.
- Управляемые фикстуры данных: миграции, сидирование, очистка после теста, предсказуемые таймзоны/локали.
- Тестовые doubles для внешних сервисов: sandbox/стаб, либо локальный эмулятор, либо записанные ответы (где допустимо).
- Контракты: OpenAPI/AsyncAPI/Proto‑схемы как источник правды, чтобы интеграционные проверки были точными.
- Доступы и лимиты: токены, rate‑limits, политика хранения логов (особенно если данные чувствительные).
Быстрый чек‑лист: интеграционные тесты без переплат
- Тест проверяет один стык и один результат (контракт/инвариант), без лишних переходов по UI/HTTP цепочке.
- Нет зависимостей от реального времени: таймеры и ретраи контролируемы.
- Данные теста создаются внутри теста и удаляются внутри теста (или в рамках транзакции/тейрдауна).
- Ошибки диагностируются по логам/трейсам без ручного дебага "наугад".
E2E‑тесты: какие сценарии оставить для реального покрытия
E2E тестирование самое дорогое и хрупкое, поэтому оставляйте только те сквозные сценарии, которые реально доказывают работоспособность продукта для пользователя и не покрываются дешевле. Цель - не "проверить всё", а гарантировать, что критичные цепочки не сломались после изменений.
Риски и ограничения перед стартом e2e
- Флейки из‑за асинхронности: ожидания событий/рендеринга и гонки делают прогон нестабильным.
- Высокая цена поддержки: малые изменения UI/маршрутов могут ломать множество тестов одновременно.
- Зависимость от окружения: сеть, тестовые данные, фоновые джобы, очереди, интеграции могут давать шум.
- Слепые зоны: e2e часто не объясняет причину падения (симптом на UI, причина в сервисе/данных).
Пошаговая инструкция: отбор и постановка e2e без лишних сценариев
-
Соберите "тонкий" список критичных пользовательских путей.
Оставьте только цепочки, где цена дефекта максимальна: оплата, регистрация, оформление заказа, изменение тарифов, выгрузка отчёта. Один путь - один бизнес‑результат.- Формулируйте как: "пользователь делает X и получает Y", без деталей реализации.
- Старайтесь удержать сценарий в пределах одного логического потока без ответвлений.
-
Разрежьте сценарий по слоям и выкиньте то, что дешевле проверить ниже.
Поля/валидации/пересчёты переносите в unit‑тестирование, контракты API - в контрактные/интеграционные проверки. В e2e оставляйте только доказательство, что слои связались и дали итог.- Если падение можно поймать unit или интеграционно быстрее - e2e для этого не нужен.
-
Стабилизируйте тестовые данные и состояние системы.
Создавайте данные через API/прямые фикстуры, а не кликами в UI. Делайте идемпотентный setup и гарантированный teardown, чтобы тест не зависел от "хвостов" прошлых прогонов.- Ограничьте использование глобальных общих аккаунтов и "вечных" сущностей.
- Фиксируйте время (clock) там, где это влияет на результат.
-
Встройте наблюдаемость и понятные ошибки.
На падение e2e должно приходить: скриншот/видео (если UI), сетевой лог, correlation id, ссылки на логи сервисов. Иначе вы платите временем за ручной поиск причин.- В тестах логируйте ключевые шаги и бизнес‑идентификаторы (orderId, userId).
-
Закрепите стратегию запуска: PR vs nightly.
Минимальный smoke‑набор запускайте на PR, расширенный регресс - по расписанию. Так e2e тестирование не блокирует разработку и остаётся полезным.- Падение smoke на PR должно быть максимально редким и воспроизводимым.
Сокращаем время тестирования: приоритеты, параллелизм и ранняя фильтрация
Скорость достигается не "ускорением всего сразу", а правильным порядком: сначала дешёвые и быстрые проверки, потом более дорогие. Параллелизм и кэширование помогают только после того, как тесты стали детерминированными и независимыми.
Проверка результата: чек‑лист ускорения без потери надёжности
- На PR сначала идут линтер/форматтер/типизация и быстрые unit‑тесты; более дорогие уровни запускаются после успешной ранней фильтрации.
- Набор тестов разделён на группы: быстрые (PR), расширенные (merge), полный регресс (nightly/перед релизом).
- Тесты параллелятся без конфликтов: нет общих mutable‑ресурсов, уникальные схемы/неймспейсы/топики на прогон.
- Флейки устраняются до масштабирования параллельности; иначе параллелизм умножает шум.
- Самые медленные тесты вынесены в отдельный job и видны в отчёте (чтобы было что оптимизировать).
- Используются повторяемые фикстуры и контроль времени/случайности (seed), чтобы прогон был воспроизводим.
- Тесты написаны так, чтобы падение давало причину (assert по инвариантам, а не по косвенным признакам).
- Если вы покупаете услуги тестирования ПО у подрядчика, у вас определены SLA на время обратной связи и формат артефактов (логи/видео/репорты), иначе экономии не будет.
Окружения, заглушки и контрактное тестирование: экономия усилий без рисков
Заглушки, фейки и контрактные тесты ускоряют разработку, если вы не подменяете ими реальность там, где важны протоколы, гарантии доставки и совместимость. Правильный принцип: мокайте поведение, но фиксируйте контракт и проверяйте его отдельно.
Частые ошибки, из-за которых "экономия" превращается в риск
- Моки повторяют реализацию вместо контракта: тесты зелёные, а интеграция ломается после реального ответа сервиса.
- Слишком "умные" фейки: в фейке случайно реализована логика иначе, чем в проде, и тесты вводят в заблуждение.
- Нет версии контрактов: изменения в API не ловятся заранее и приходят поломкой на e2e или в прод.
- Заглушка не моделирует ошибки/таймауты: код ретраев и деградации не проверен.
- Общие тестовые окружения без изоляции: тесты начинают зависеть друг от друга и "плавают".
- Секреты и токены используются напрямую в CI без минимизации прав и ротации: риск утечки и блокировок.
- Невалидные тестовые данные: код проходит тесты, но падает на прод‑валидациях (форматы, кодировки, ограничения длины).
- Контрактные проверки не встроены в пайплайн: они существуют, но не предотвращают мердж несовместимых изменений.
Метрики, которые показывают переплаты по времени и когда нужно рефакторить
Смысл метрик - не "считать ради отчёта", а подсветить места, где вы платите временем: медленные тесты, флейки, дорогая поддержка. Ниже - варианты действий, когда метрики показывают проблему.
Альтернативы и решения, когда набор тестов стал слишком дорогим
-
Перенос проверок на более дешёвый уровень.
Если дефект почти всегда ловится на e2e, но его причина - бизнес‑логика, перенесите проверку в unit тестирование и оставьте в e2e только один "доказательный" сценарий. -
Замена части интеграционных проверок контрактными тестами.
Если интеграционные тесты медленные из‑за окружений, фиксируйте API‑контракты и валидируйте совместимость на сборке провайдера/консьюмера. -
Разделение e2e на smoke и регресс + стабилизация вместо расширения.
Если e2e часто падают и тормозят PR, урежьте PR‑набор до smoke, а усилия направьте на устранение флейков и детерминизм данных. -
Пересборка пайплайна и наблюдаемости.
Если много времени уходит на диагностику, добавьте артефакты, трассировку и отчёты по самым медленным/часто падающим тестам; это обычно быстрее, чем бесконечное "ускорение" железом.
Ответы на типовые сомнения и управляемые риски
Сколько e2e‑тестов нужно, чтобы "спать спокойно"?
Ровно столько, чтобы покрыть критичные пользовательские пути и smoke‑проверку релиза. Остальное выгоднее закрывать unit и интеграционным тестированием, иначе вы переплачиваете поддержкой и флейками.
Почему unit тестирование не ловит баги интеграции, даже если всё замокано?
Моки подтверждают ваши ожидания, но не реальный контракт внешней системы. Для этого нужны интеграционные или контрактные проверки, которые валидируют формат, статусы, схемы и ошибки.
Когда интеграционное тестирование превращается в скрытое e2e?
Когда тест поднимает много компонентов сразу, проходит через несколько сетевых границ и проверяет UI/полный флоу вместо одного стыка. Такой тест обычно медленный и плохо диагностируемый.
Как уменьшить флейки в e2e тестировании без переписывания всего набора?
Стабилизируйте данные (setup через API), уберите ожидания "на глаз" в пользу явных условий, изолируйте окружение и добавьте артефакты для разбора падений. После этого сокращайте сценарии до самых ценных.
Что делать, если автоматизация тестирования тормозит команду, а ручная проверка кажется быстрее?
Ограничьте автоматизацию на PR до быстрых проверок и smoke, а сложный регресс запускайте по расписанию. Автоматизируйте только то, что часто повторяется и дорого проверяется вручную.
Как выбирать между собственной командой и услугами тестирования ПО?
Если нужна постоянная быстрая обратная связь и тесная работа с кодом - выгоднее внутренняя компетенция. Если пик нагрузки нерегулярен или нужен узкий тип проверок, услуги тестирования ПО уместны при чётком SLA на время прогона и качество отчётов.
Можно ли держать тесты стабильными, если продукт быстро меняется?
Да, если тестировать контракты и инварианты, а не детали UI, и если у каждого слоя есть своя роль в пирамиде. Быстрее всего ломаются тесты, которые проверяют не то, что обещает система, а то, как она сейчас устроена.